
Nvidia (NVDA): O discurso principal do GTC e o debates de capex e inferência
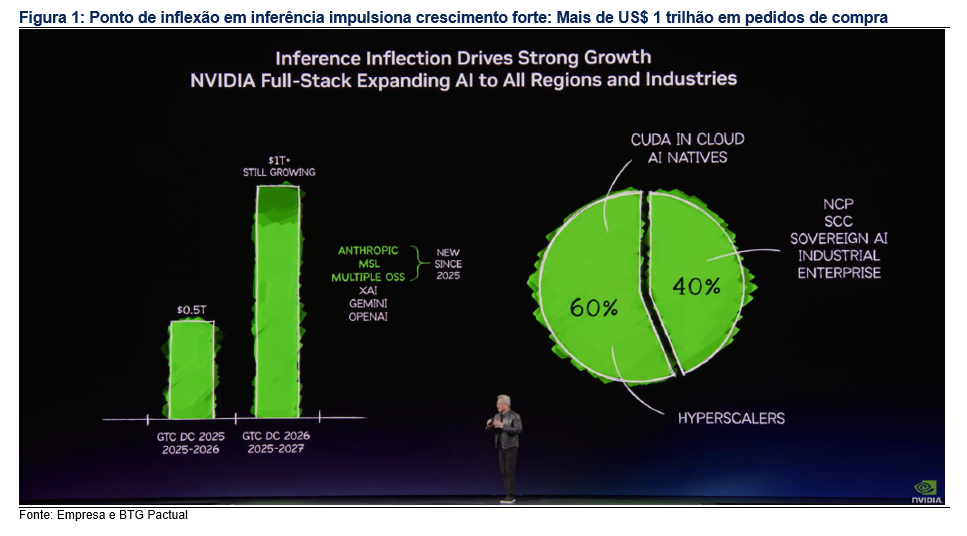
Ver Relatório CompletoParticipamos do discurso principal do CEO Jensen Huang no GTC 2026, em San Jose. Acreditamos que o evento entregou em duas expectativas centrais dos investidores. Primeiro: A Nvidia trouxe visibilidade à frente para uma trajetória forte de crescimento em 2027 ao divulgar mais de US$ 1 trilhão em pedidos de compra de data center até 2027, cobrindo Blackwell e Vera Rubin, em linha com nossas estimativas e acima do consenso atual. Vemos isso como um fator que ajuda a endereçar preocupações remanescentes sobre “pico de capex” em 2026. Segundo: O lançamento do rack de inferência Groq LPX reforça o compromisso da Nvidia com o mercado de inferência, que enxergamos como um vetor crítico e cada vez mais competitivo de crescimento dentro da infraestrutura de IA. A ação fechou em alta de 1,65% a US$ 183,22, abaixo das máximas intradiárias de cerca de 4,8% após a divulgação do US$ 1 trilhão. Seguimos vendo catalisadores positivos à frente, incluindo maior clareza de capex de hyperscalers para 2027 e novos LLMs treinados em Blackwell, que devem reforçar a liderança de performance da Nvidia.
Hardware: Estratégia intacta, arquitetura de inferência agora completa
Vera Rubin NVL72: A plataforma de fábrica de IA de próxima geração da Nvidia foi confirmada como já em produção no Microsoft Azure, não apenas como um slide de estratégia, mas como hardware implantado. O Rubin Ultra, 144 GPUs em 2027, e a arquitetura de rack vertical Kyber estendem ainda mais a curva de densidade de compute, enquanto a estratégia Feynman para 2028, integrando uma nova GPU, LPU e a CPU “Rosa”, oferece aos clientes uma estratégia arquitetural clara de três anos. Qualquer empresa ou hyperscaler que esteja tomando decisões de infraestrutura hoje, na prática, está se comprometendo com a carga de trabalho da Nvidia no horizonte previsível.
Groq 3 LPU, o anúncio estrategicamente mais relevante: O primeiro chip oriundo da aquisição de ativos da Groq por US$ 20 bilhões, em dezembro de 2025, está programado para acontecer no terceiro trimestre de 2026. O rack LPX, com 256 LPUs, foi desenhado para operar ao lado do sistema em escala de rack Vera Rubin e entrega 35x mais produto final por watt e uma oportunidade de receita 10x maior para modelos de trilhões de parâmetros versus a plataforma Blackwell. De forma crítica, essa arquitetura resolve o trade-off de produto final versus latência que vinha sendo o “teto” estrutural da monetização de inferência, permitindo uma precificação premium em camadas para cargas de trabalho de IA de agentes mais complexos. Entendemos que isso endereça diretamente o desafio de data centers cada vez mais limitados por energia, ao mesmo tempo em que abre novos vetores de monetização. Investidores que esperavam que a Nvidia cedesse a economia de inferência para silício customizado, como TPUs do Google e a linha MI da AMD, devem revisitar essa premissa após a divulgação. Jensen também indicou que versões futuras do LPX estarão presentes nas próximas gerações de arquitetura, reforçando que não se trata de uma resposta de um ciclo, e sim de um pilar estrutural de produto.
Estratégia protege custo de troca: O aniversário de 20 anos do CUDA é um pano de fundo apropriado. Nenhum concorrente está entregando uma camada integrada de GPU, LPU e CPU dentro desse cronograma. O Space-1 Vera Rubin, data centers orbitais, não está no nosso modelo, mas reforça o caráter de longa duração da tese de demanda do Jensen.
Software e IA de agentes: Mudança de plataforma fica explícito
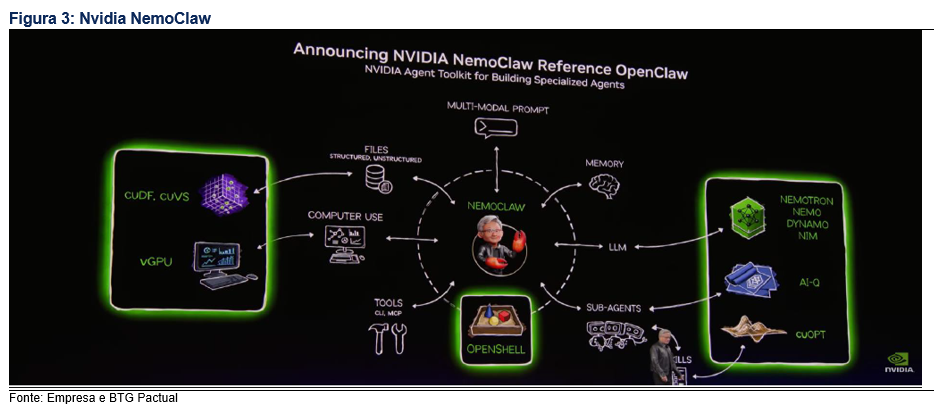
O NemoClaw foi anunciado como a carga de open source de IA de agentes da Nvidia para empresas, em conjunto com os sistemas DGX Spark e DGX Station, voltados à implantação de agentes autônomos, de longa duração, no desktop e dentro de ambientes corporativos. O enquadramento do Jensen de OpenClaw como o “Windows da computação de agentes”, e a afirmação de que toda empresa precisa de uma estratégia de OpenClaw, é um movimento deliberado de posicionamento. Isso amplia o mercado endereçável da Nvidia de silício para software e camada de aplicações, com implicações potenciais de receita recorrente que ainda não estão refletidas nas estimativas de consenso.
Setor Automotivo e IA física: Desconto fica mais difícil de justificar
O mercado tem precificado de maneira inadequada a exposição da Nvidia a IA física. Os anúncios recentes reforçam que esse segmento merece mais crédito. A parceria com a Uber, frotas autônomas em 28 cidades em quatro continentes até 2028, fornece um dado de implantação comercial em escala que valida o Drive Hyperion como uma plataforma geradora de receita, e não uma demonstração tecnológica. Nissan, BYD, Geely, Isuzu e Hyundai foram confirmadas como parceiras de AV nível 4 no Drive Hyperion, ampliando a exposição das montadoras em diversas geografias, com destaque para a inclusão da BYD, que adiciona exposição ao mercado chinês sem risco de tarifas para o silício da Nvidia. O enquadramento do Jensen de um “momento ChatGPT” para direção autônoma se alinha à validação comercial implícita nesses compromissos.
Em robótica, a demonstração do robô Olaf, treinado em simulação Omniverse e DeepMind, é mais “teatro” para o consumidor, mas o ponto central de que a simulação do Omniverse está emergindo como ambiente dominante de treinamento para IA física, tem implicações reais para empresas em manufatura, logística e saúde. Esperamos que isso se torne uma contribuição mais material de receita na janela de 2028 a 2029.
O que muda na tese de investimento
Duração do ciclo de capex: O argumento dos pessimistas com a tese de investimento mais persistente contra a Nvidia tem sido o risco de redução do capex dos clientes em 2026 e 2027. A divulgação de US$ 1 trilhão em pedidos de compra, cobrindo computação e networking, endereça diretamente essa preocupação. Isso deve ancorar o ciclo de revisões de consenso para 2027 e aumentar a convicção que o sell-side vinha relutando em incorporar.
Trajetória de mix de produtos com a Integração de LPU e software NemoCla deve gerar receita incremental e alta margem. O perfil de margem bruta em 2027 e 2028 pode ser materialmente melhor do que o que os modelos de sell-side hoje precificam, especialmente se o modelo premium de precificação em camadas para workloads de inferência com Groq ganhar tração. Vemos isso como cenário otimista versus nossas estimativas atuais, e não como revisão de cenário-base.
Vantagem competitiva: A base instalada de 20 anos do CUDA, combinada a uma camada integrada de hardware, inferência e software que nenhum concorrente consegue igualar nesse cronograma, reforça o argumento de vantagem competitiva estrutural. A AMD tem hardware competitivo, mas não tem a profundidade de ecossistema nem a integração full stack. A integração do Groq LPU, em particular, atacando diretamente a curva de custo de inferência que concorrentes de silício customizado eram esperados dominar, é uma resposta competitiva relevante.
Visibilidade melhorou e a tese de inferência se fortaleceu
Fomos ao keynote com duas perguntas: Jensen entrega visibilidade suficiente para neutralizar o debate de “pico de capex”, e a Nvidia tem uma resposta crível para a ameaça competitiva em inferência? A resposta para ambas é sim. A divulgação do US$ 1 trilhão ancora o debate de receita de 2027, e o rack Groq LPX é uma resposta tecnicamente crível ao desafio de economia de inferência. O NemoClaw representa a evidência inicial de uma camada de receita de software que, se se desenvolver, pode justificar uma expansão relevante de múltiplos ao longo do tempo.